![]() UltraEdit
UltraEdit
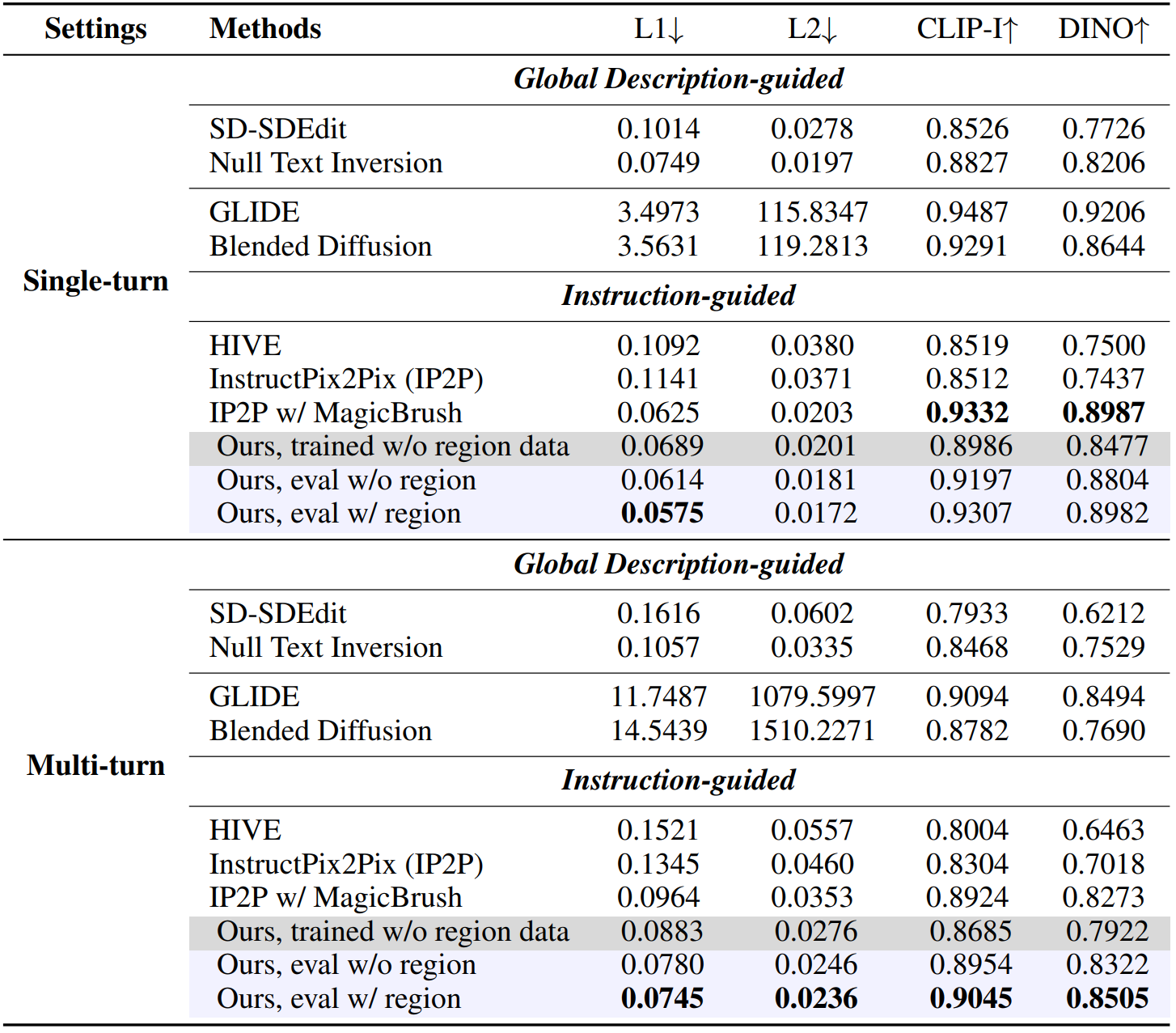
Construction of UltraEdit:
(Upper)
We use LLM with in-context examples to produce editing instructions and target captions given the collected image captions.
(Middle)
For free-form editing, we use the collected images as anchors, and invoke regular diffusion followed by prompt-to-prompt (P2P) control to produce source and target images.
(Bottom)
For region-based editing, we first produce an editing region based on the instruction, then invoke a modified inpainting diffusion pipeline to produce the images.
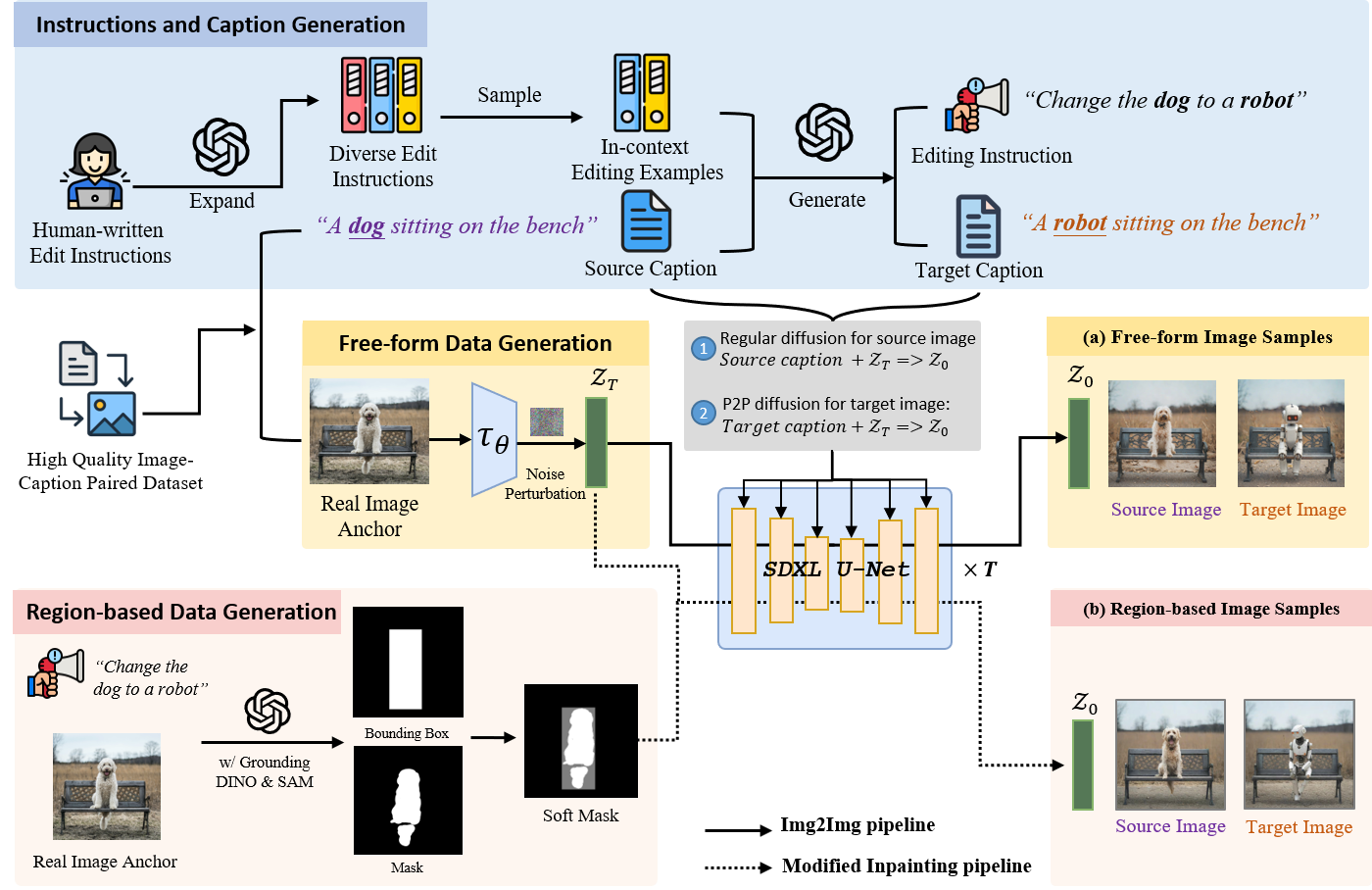
Comparison of different image editing datasets. Both EditBench and MagicBrush are manually annotated but are limited in size.
InstructPix2Pix and HQ-Edit are large datasets automatically generated using T2I models like
Stable Diffusion and DALL-E, though they present notable biases from the generative models leading to failure cases.
UltraEdit offers large-scale samples with rich editing tasks and fewer biases.
![]() Example
Example
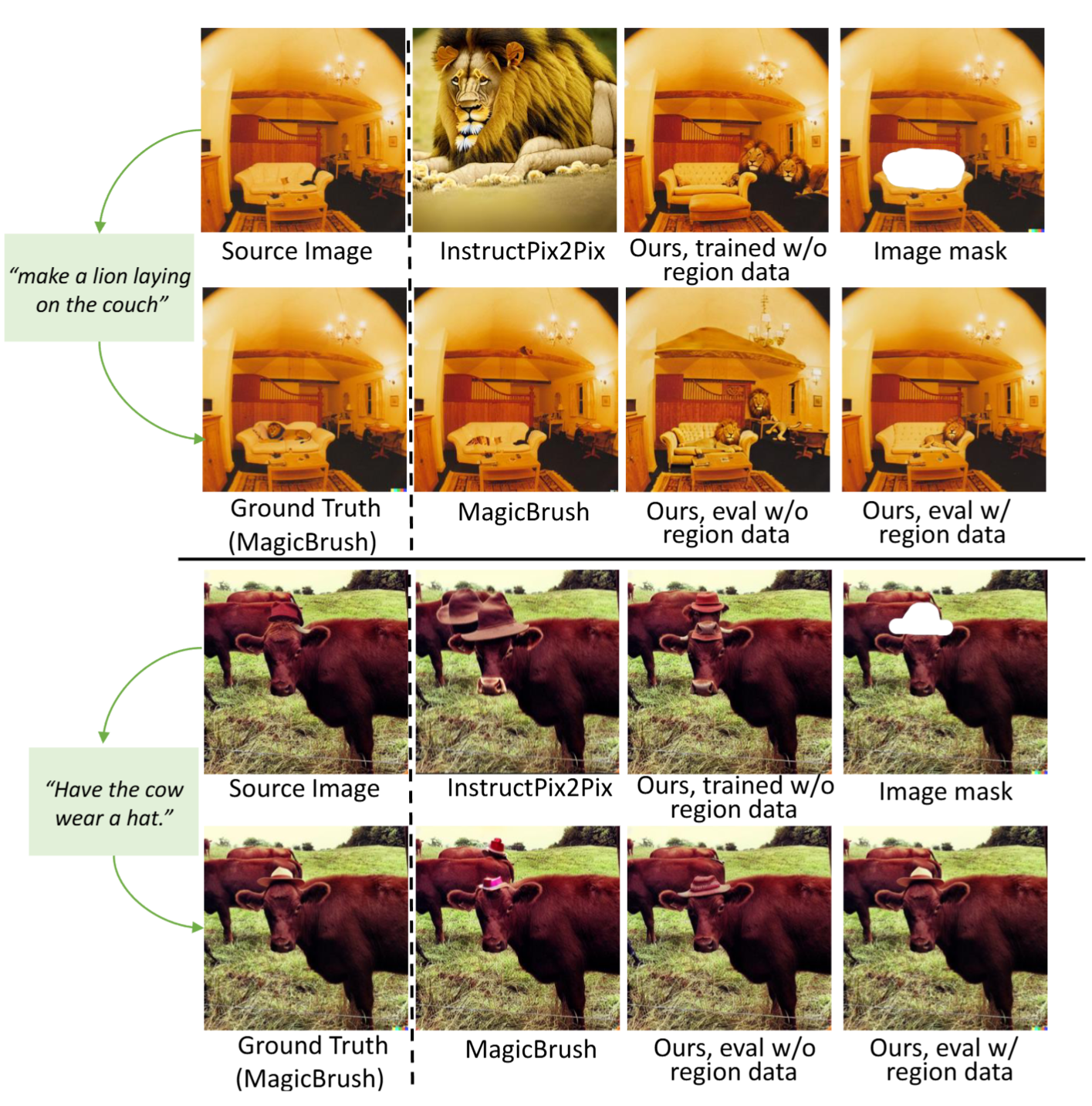
Examples of UltraEdit. Free-form and Region-based Image Editing

![]() Statistics
Statistics
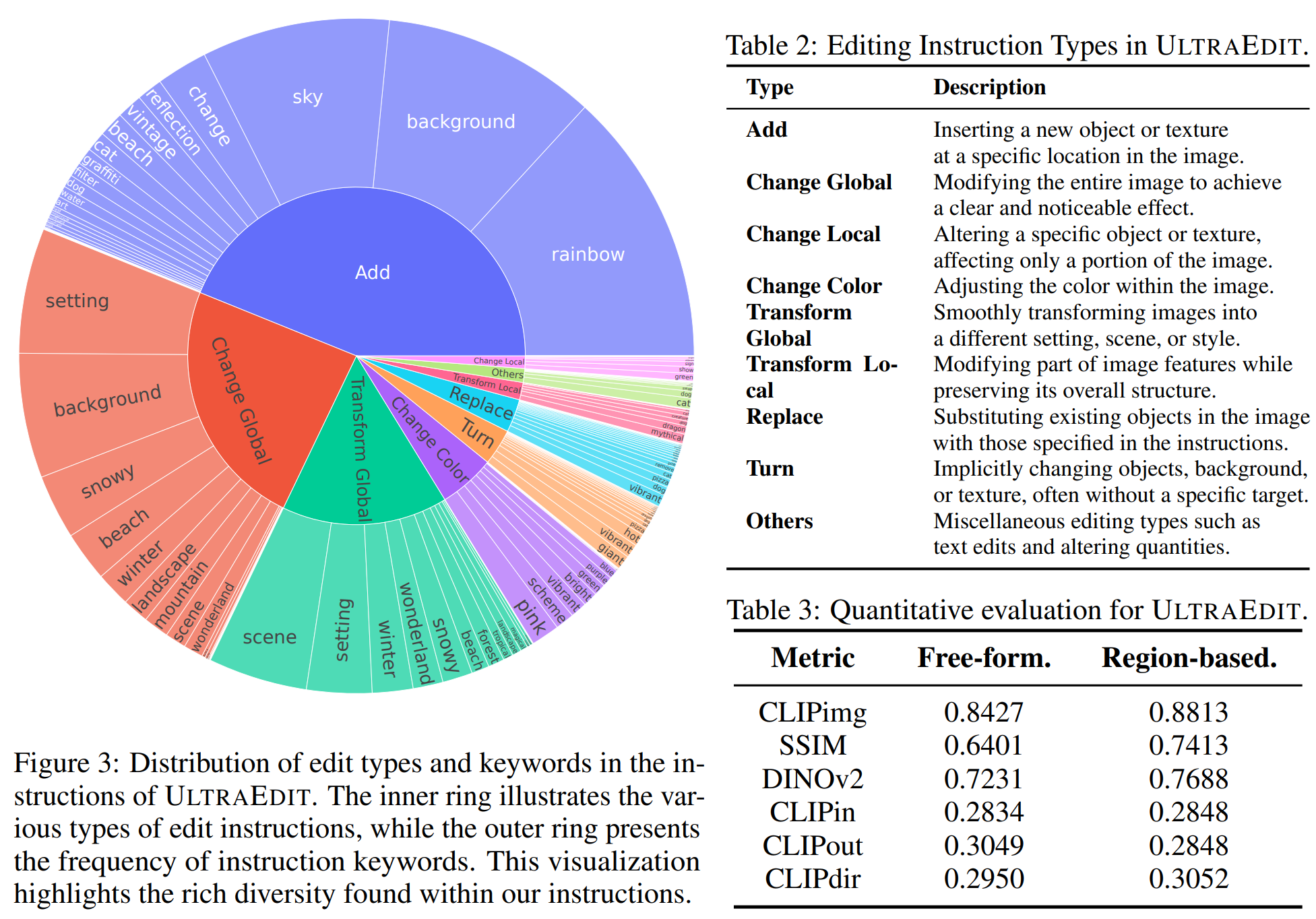
Statistics of Free-form and Region-based Image Editing Data. The following table shows the instance numbers, number of unique instructions, and their respective proportions for different instruction types.
![]() Editing Examples
Editing Examples
The Editing examples generated by Stable Diffusion3 trained with UltraEdit dataset. It supports both free-form (without mask) and region-based (with mask) image editing. You can try this model in the above Demo.
| Input Image | Edit Instruction | Edited Images |
|---|---|---|

|
Add a UFO in the sky |

|

|
Add a moon in the sky |

|

|
add cherry blossoms |

|

|
Please dress her in a short purple wedding dress adorned with white floral embroidery |

|

|
give her a chief's headdress. |

|